
{kind=link}

Think about typing “dramatic intro music” and listening to a hovering symphony or writing “creepy footsteps” and getting high-quality sound results. That is the promise of Secure Audio, a text-to-audio AI mannequin introduced Wednesday by Stability AI that may synthesize music or sounds from written descriptions. Earlier than lengthy, comparable expertise could problem musicians for his or her jobs.
In the event you’ll recall, Stability AI is the corporate that helped fund the creation of Secure Diffusion, a latent diffusion picture synthesis mannequin launched in August 2022. Not content material to restrict itself to producing pictures, the corporate branched out into audio by backing Harmonai, an AI lab that launched music generator Dance Diffusion in September.
Now Stability and Harmonai need to break into business AI audio manufacturing with Secure Audio. Judging by manufacturing samples, it looks as if a major audio high quality improve from earlier AI audio turbines we have seen.
On its promotional web page, Stability supplies examples of the AI mannequin in motion with prompts like “epic trailer music intense tribal percussion and brass” and “lofi hip hop beat melodic chillhop 85 bpm.” It additionally provides samples of sound results generated utilizing Secure Audio, similar to an airline pilot talking over an intercom and folks speaking in a busy restaurant.
To coach its mannequin, Stability partnered with inventory music supplier AudioSparx and licensed a knowledge set “consisting of over 800,000 audio information containing music, sound results, and single-instrument stems, in addition to corresponding textual content metadata.” After feeding 19,500 hours of audio into the mannequin, Secure Audio is aware of learn how to imitate sure sounds it has heard on command as a result of the sounds have been related to textual content descriptions of them inside its neural community.
Stablility AI
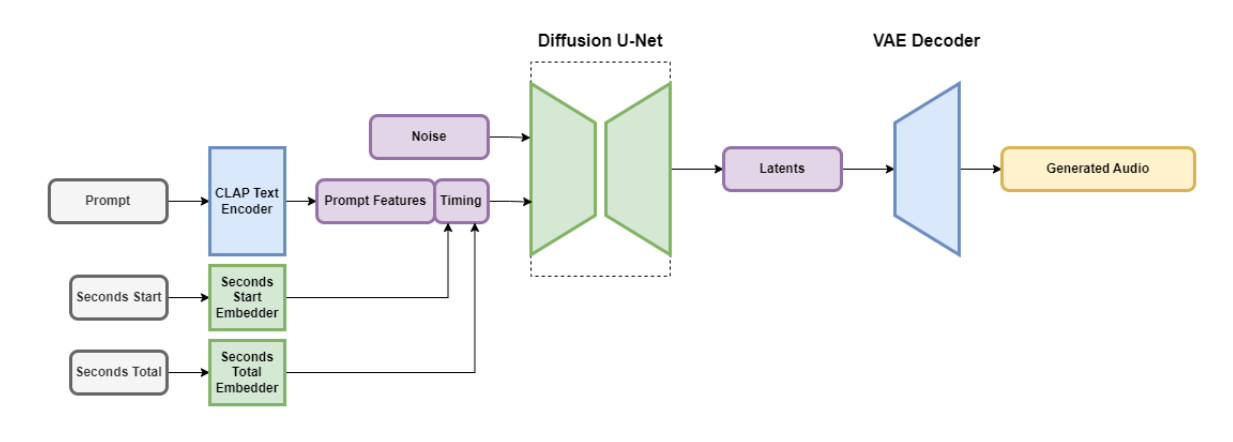
Secure Audio incorporates a number of elements that work collectively to create personalized audio rapidly. One half shrinks the audio file down in a approach that retains its necessary options whereas eradicating pointless noise. This makes the system each sooner to show and faster at creating new audio. One other half makes use of textual content (metadata descriptions of the music and sounds) to assist information what sort of audio is generated.
To hurry issues up, the Secure Audio structure operates on a closely simplified, compressed audio illustration to cut back inference time (the period of time it takes for a machine studying mannequin to generate an output as soon as it has been given an enter). Based on Stability AI, Secure Audio can render 95 seconds of stereo audio at a 44.1 kHz pattern fee (usually known as “CD high quality”) in lower than one second on an Nvidia A100 GPU. The A100 is a beefy knowledge heart GPU designed for AI use, and it’s miles extra succesful than a typical desktop gaming GPU.
As talked about, Secure Audio is not the primary music generator primarily based on latent diffusion methods. Final December, we coated Riffusion, a hobbyist tackle an audio model of Secure Diffusion, although its ensuing generations had been removed from Secure Audio’s samples in high quality. In January, Google launched MusicLM, an AI music generator for twenty-four kHz audio, and Meta launched a collection of open supply audio instruments (together with a text-to-music generator) known as AudioCraft in August. Now, with 44.1 kHz stereo audio, Secure Diffusion is upping the ante.
Stability says Secure Audio shall be obtainable in a free tier and a $12 month-to-month Professional plan. With the free possibility, customers can generate as much as 20 tracks per thirty days, every with a most size of 20 seconds. The Professional plan expands these limits, permitting for 500 observe generations per thirty days and observe lengths of as much as 90 seconds. Future Stability releases are anticipated to incorporate open supply fashions primarily based on the Secure Audio structure, in addition to coaching code for these eager about creating audio era fashions.
Because it stands, it is wanting like we could be on the sting of production-quality AI-generated music with Secure Audio, contemplating its audio constancy. Will musicians be glad in the event that they get changed by AI fashions? Possible not, if historical past has proven us something from AI protests within the visible arts discipline. For now, a human can simply outclass something AI can generate, however that is probably not the case for lengthy. Both approach, AI-generated audio could turn into one other instrument in an expert’s audio manufacturing toolbox.